



데이터센터 한곳 장애 때 다른 곳으로 연결 초고속 전환
서로 멀리 떨어진 지역 데이터센터 최소 3곳 이용이 일반적

(샌프란시스코·서울=연합뉴스) 김태종 특파원 임화섭 기자 = 지난 15일 발생한 SK C&C 판교 데이터센터 화재와 이에 따른 카카오 계열사들의 장시간 서비스 장애를 계기로 글로벌 정보기술(IT) 대기업들의 데이터센터 운영에 관심이 쏠리고 있다.
기업들이 서버를 관리하는 방식은 업태와 규모 등에 따라 다양하다.
가장 전통적 방식은 원격 시설을 쓰지 않고 사무실 내 등 현장에 서버를 두고 관리하는 '온프레미스'(On-premises)다. 수십년 전 기업들이 전산실을 설치해 놓고 자사가 보유 혹은 임차한 중대형 컴퓨터를 놓고 여기 소프트웨어를 설치해 돌리던 것과 같은 방식이 이에 해당하지만, 비용·인력 등 효율성 문제로 요즘은 이렇게 하는 경우가 드물다.
이 때문에 수많은 서버를 두고 각종 데이터를 처리하고 저장하도록 하는 '데이터 센터'에 고객으로 들어가는 것이 일반화됐다.
이번에 화재가 난 곳이 바로 SK C&C가 운영하는 판교 데이터센터였으며, 카카오는 이 곳에 고객사로 입주해 수만대의 서버들을 두고 있었다.
한때는 데이터 센터 측이 장소를 제공하면서 물리적 안전확보, 전력공급, 통신유지 등 기본적 관리만 하고 개별 서버는 고객 기업이 소유하거나 임차하는 경우도 없지 않았으나, 요즘은 서버 자체는 데이터센터가 관리하되, 고객사들은 서버를 이용할 수 있는 권리를 시간과 용량에 따라 사들이는 경우도 흔해졌다.
아마존, 마이크로소프트, 구글 등 대형 테크 기업들은 막대한 투자를 통해 자체 데이터센터를 보유하고 관리하는 것은 물론, 다른 기업들을 고객으로 삼아 이런 방식으로 컴퓨팅 자원을 제공하는 '클라우드 서비스'를 통해 막대한 수익을 창출하고 있다.
아마존은 '아마존 웹서비스'(AWS), 마이크로소프트(MS)는 '애저'(Azure), 구글은 '구글 클라우드 플랫폼'(GCP)이라는 이름으로 각각 클라우드 사업을 하고 있다. 글로벌 클라우드 시장점유율은 기준이나 조사기관에 따라 다르지만 대체로 AWS가 40%, 애저가 20%, 구글이 10% 수준인 것으로 평가된다.
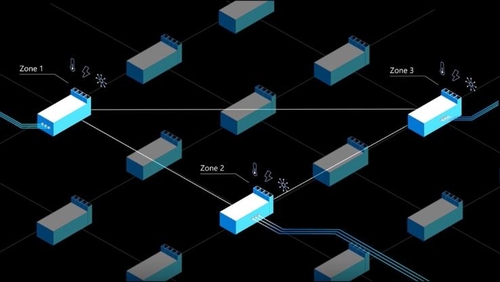
AWS, 애저, GCP는 각각 전 세계에 수십개의 데이터센터를 운영하고 있으며, 화재나 재난에 대비해 2중, 3중의 대비를 갖추고 있다.

이 클라우드 플랫폼 기업들은 최소한 3개의 데이터센터가 상호 연결돼 데이터를 실시간으로 주고받으며 상호 백업 역할을 하도록 하고 있다.
특히 이런 클라우드 플랫폼들은 한 데이터센터에서 장애가 생기면 다른 데이터센터들이 자동으로 즉시 서비스를 이어받는 '페일오버'(fail-over) 기능을 제공한다. 이럴 경우 문제가 생긴 것을 사람이 인지해서 수동으로 '스위치오버'할 필요도 없다.
기존 서버에 문제가 생기면 예비 서버가 자동으로 작업을 넘겨받도록 해 끊김 없이 서비스를 제공할 수 있도록 하는 것이다.
이는 서로 떨어져서 독립적으로 운영되는 데이터센터들이 초고속 고성능 네트워크를 통해 서로 연결된 상태에서 서비스 응답을 제공하기 때문에 가능한 일이다.
클라우드 플랫폼 업체들과 여기 입주한 주요 IT 대기업들은 비상사태에 대비하기 위해 평상시에도 서버 전체가 마비되는 극단적인 상황을 가정한 훈련을 하는 경우가 드물지 않다.
의도적으로 클라우드 서비스를 마비시키거나 특정 시점에 경고 없이 인프라를 마비시켜 약점을 노출시킴으로써 더 나은 복구 시스템을 구축하기도 한다.
이럴 때조차 서비스는 끊김 없이 진행되기 때문에 고객들이 장애를 알아차리지 못하는 경우가 오히려 더 흔하다.
카카오 정도 규모의 대형 IT기업에서 이번 사고처럼 핵심 서비스가 모조리 심각한 장애를 장시간 겪은 경우는 세계 IT기업 역사상 유례를 찾기 힘들다. IT 대기업들의 경우 일부 데이터 센터에서 장애가 생기더라도 '무중단'으로 서비스가 제공되도록 해 놓는 것이 오히려 글로벌 표준에 가깝다.
구글의 경우 1년에 2번 이상 재해 복구 계획을 테스트하고 있다.
실리콘밸리의 한 테크 기업에 다니는 엔지니어는 "데이터센터끼리 연동해 실시간 백업은 데이터 관리의 기본이 됐다"며 "높은 비용 문제로 완전 백업은 아니더라도 두 데이터센터 저장을 50대 50으로 조정해 문제가 생기면 한쪽으로 모는 방법을 쓰기도 한다"고 말했다.
taejong75@yna.co.kr, limhwasop@yna.co.kr
(끝)
<저작권자(c) 연합뉴스, 무단 전재-재배포 금지>
