

역사 퀴즈 풀고 사투리·욕설 순화도 가능…"개인정보는 제거·비식별 처리"
(서울=연합뉴스) 홍지인 기자 = 네이버 만든 국내 최초의 초(超)대규모 인공지능(AI) '하이퍼클로바'는 한국어 학습을 위해 네이버의 주요 서비스에서 사용자가 남긴 다양한 자료를 활용한 것으로 나타났다.
강인호 자연어처리 책임리더는 25일 '네이버 AI 나우' 콘퍼런스에서 "딥러닝에서 중요한 것 중 하나는 좋은 데이터를 확보해서 사용하는 것"이라며 "한국에 있는 전반적 데이터를 가져다 놓고 품질이 좋은 순서대로 가져왔다"고 말했다.
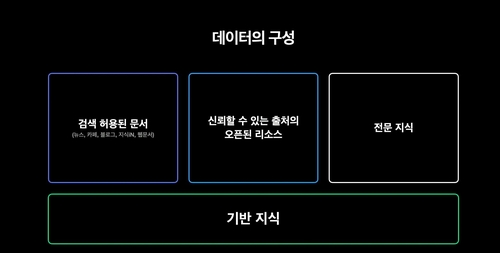
먼저 정보의 범용성과 완결성을 고려해 객관적 사실 중심의 기반 지식을 마련했다.
여기에 뉴스·카페·블로그·지식인·웹문서 등 검색이 허용된 문서에서 좋은 품질 순서로 줄을 세웠다.
정부 기관 웹페이지나 사이트는 정보 가치가 일정 수준 이상인 영역만 포함했고, 의미 없는 단어 나열이나 자소 단위 반복, 비속어는 제거했다.
강 리더는 "검색 로그와 서비스 로그를 통해 어느 출처의 어느 문서가 정보 제공처로 유용한지, 인기가 있는지 잘 파악하고 있다"며 "정보성과 신뢰도 있는 공식 사이트 및 인기 있는 출처가 상위 품질에 많이 포함되도록 했다"고 말했다.

국립국어원이 만든 '모두의 말뭉치'처럼 이미 만들어진 AI 학습용 한국어 데이터 세트는 고품질 출처로 간주해 추가하고, 다양성 확보 차원에서 전문 지식도 포함했다.
이렇게 만들어진 한국어 데이터 세트는 1.96테라바이트(TB) 크기다. 한국어 위키피디아의 2천900배로, 뉴스 50년 치에 해당한다.
이 데이터를 학습시킨 AI로 한국 역사 퀴즈를 풀거나 사투리를 표준어로 바꾸고, 욕설을 순화하는 작업 등이 가능했다.
강 리더는 "한국 지식과 한국어 특성을 잘 반영한 좋은 구성"이라며 "지금 우리가 구할 수 있는 한국어 문서의 결정체"라고 내세웠다.
AI 학습을 위한 자료 수집에 있어 가장 민감한 부분이 사용자 개인정보 처리 문제다.
강 리더는 "개인정보 수집을 지양하고 있다"면서도 "사용자들이 '전체 공개'로 지정해 수집되는 정보들, 검색을 허용한 문서들에 대해서 혹시 포함될 수 있을지 모를 개인정보는 제거하거나 비식별 처리 진행하고 있다"고 말했다.
ljungberg@yna.co.kr
(끝)
<저작권자(c) 연합뉴스, 무단 전재-재배포 금지>