



“한국판 뉴딜에는 데이터 라벨링을 하기 위한 청년 일자리 10만개가 들어가 있다. 데이터 라벨링 작업 자체는 단순한 작업이지만 조직 내에서 하다보면 얻는 경험을 가지고 어떤 분야에 더 활용할 수 있을 것이다.”(김상조 청와대 정책실장)
문재인 정부는 지난 14일 신산업 분야에 160조원을 투자해 190만개의 일자리를 만든다는 '한국판 뉴딜 종합계획'을 발표했다. 이 중 정부가 내세운 대표적인 간판 사업이 '데이터 댐' 구축이다. 수많은 데이터를 수집하고 정리해 데이터 산업 발전의 발판으로 삼겠다는 계획이다. 데이터 수집 및 가공을 뜻하는 '데이터 라벨링'은 취업난을 겪는 청년들에게 주로 맡기기로 했다. 정부는 이로 인해 창출되는 일자리가 10만개에 이를 것으로 예상했다.
하지만 전문가들은 "정부 주도의 데이터 라벨링은 막대한 예산만 낭비하고 실제 산업에서 쓸 수 없는 데이터만 양산할 가능성이 높다"고 우려하고 있다. 정책 목표가 신산업 발전이 아닌 '단기 일자리 제공'에 매몰되면서, IT업계에서 통용되는 '가비지 인, 가비지 아웃(garbage in, garbage out)'이라는 말처럼 질 낮은 데이터만 대량으로 양산될 수 있다는 우려다. 데이터 라벨링이 무엇이고, 실제로 관련 일자리는 어떤 모습인지 직접 체험해 정리했다.
'데이터경제 핵심' 데이터 라벨링이 뭐길래
데이터 라벨링은 디지털 데이터에 ‘라벨’을 붙이는 작업이다. 과학기술정보통신부는 ‘기술·산업적으로 유망하고 AI응용개발에 공통적으로 활용 가능한 이미지·영상 등 범용성 높은 인공지능(AI) 데이터를 구축하는 것’으로 정의하고 있다. 이렇게 구축한 데이터는 인공지능(AI)이 학습하는 '교과서'로 쓰인다.예컨대 개의 사진을 보고 견종이 무엇인지 판별해 주는 서비스를 개발한다고 하자. 전문가들은 개의 사진을 보면 견종을 높은 정확도로 빠르게 파악할 수 있다. 하지만 AI에게는 사사진의 어떤 부분이 '개'에 해당하는지조차 정확하게 파악하기 어렵다. 사람이 하나하나 가르쳐 줄수도 없다. 빛과 주변 환경, 강아지의 모양 등에 따라 수없이 많은 경우의 수가 존재해서다.
자동학습 AI는 이런 문제를 해결할 수 있다. '학습 데이터셋'을 통해서다. 예컨대 수십만 건의 개 사진과, 개가 사진의 어느 부분에 있고 어떤 종류인지 판별해 정리한 데이터를 AI에게 쥐어 준다. AI는 먹지도 자지도 않고 빠르게 이를 학습해 사진에서 '개'를 집어내고 견종을 정확하게 판별해내는 확률을 높인다. '알파고'가 세계 최정상급의 바둑 실력을 갖추게 된 것도 비슷한 과정을 통해 이뤄졌다.
데이터셋이 많을수록, 즉 공부량이 많을 수록 AI가 실수할 확률은 낮아진다. 질 높은 데이터를 많이 공부한 AI일수록 서비스의 질이 높다는 얘기다. 데이터 산업 경쟁력을 높이려는 정부가 일반 사업자들이 활용할 수 있는 데이터를 대량으로 양산하려는 이유도 여기에 있다.
‘데이터 라벨러’ 돼보니…“인형 눈 붙이기와 비슷”
'데이터 라벨링' 일자리를 직접 체험해 봤다. 이미 민간에는 몇 개의 '데이터 라벨링 플랫폼' 업체가 있다. IT기업 등 AI 학습용 데이터를 필요로 하는 업체와 아르바이트생을 이어주고 소정의 수수료를 떼어 가는 기업들이다. 기자는 이 중 한 업체에 가입해 교육용 서비스를 체험했다. 올라온 일거리에 지원해 업무를 수행한 뒤, 업무를 제대로 수행했는 지 검사를 받아 통과되면 건당 20원에서 200원 상당의 포인트를 지급받을 수 있다. 포인트가 일정액(1000원) 이상이 되면 이를 현금화할 수 있다.건당 20원을 지급하는 '텍스트 태깅'은 간단한 언어 능력 테스트와 비슷했다. 예컨대 보고서의 일부 내용을 주고 이 중 필요한 팩트를 추려 마우스로 지정하는 방식이다. 약관이나 법조문 등 내용이 길고 가독성이 낮은 문서의 핵심을 추려서 보여주는 AI서비스 등에 활용이 가능할 것으로 보인다. 난이도는 쉬웠지만 건마다 '정답'의 기준이 다른 점은 주의가 필요했다. 예컨대 지문에서 요구하는 답으로 '데이터 인프라부문'이라는 응답은 반려되고, 반드시 '데이터 인프라'라고만 답해야 하는 식이었다.
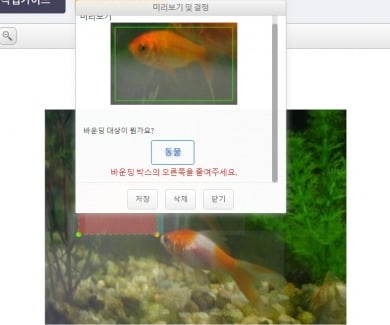
'이미지 바운딩'은 좀 더 까다로웠다. 사진 속에 있는 동물들을 마우스로 한 마리씩 표시하는 작업이다. 다른 동물 등에 가려진 부분이 있어 어디까지 표시하고 말아야 할 지 판단하기 쉽지 않았다. 범위가 조금이라도 틀리면 '반려' 메시지가 날아왔다. 이미지를 세심하게 조정하다 보니 금세 눈과 팔이 피곤해졌다.

기자는 건당 120원을 지급하는 '중급 이미지 바운딩'에서 체험을 포기했다. 큰 사진에서 차량 6~7대를 찾아 정확히 범위를 지정하는 일이었는데, 규칙이 까다로운 데다가 세심한 조정이 필요했다. 규칙은 △차량의 보이는 부분만 표시하되 △긴 안테나와 바퀴 그림자, 거울에 비친 차는 표시하면 안 되고 △지나치게 작은 차는 표시하면 안 되지만 △일정 크기 이상의 차는 표시해야 하는 등 10여가지에 달했다. 사진에 표시된 빨간 부분이 반려된 표시인데, 7~8대를 찾아 표시하면 절반 정도를 거절당하는 일이 반복됐다. 머리가 아파왔지만 ‘이 정도는 까다로워야 AI가 쓸 수 있는 양질의 데이터를 양산할 수 있겠다’는 생각이 들었다.
한 시간 가량 작업들을 완료한 뒤 기자가 번 돈은 3000원 수준. 처음 해 보는 작업이라 숙련도가 현격히 낮다는 점을 고려할 때, 익숙해지면 최저임금 정도의 돈은 벌 수 있을 것으로 예상된다. 상당한 집중력이 필요한 업무면서도 시간과 공간에 얽매이지 않고 할 수 있다는 점도 매력적이었다.
하지만 정부 관계자들이 말하는 "업무 경험을 쌓을 수 있는 일자리"와는 거리가 멀어 보였다. 육아 휴직을 하면서 해당 플랫폼을 통해 이때까지 100만원 안팎의 돈을 벌었다는 박모씨(31)는 “건당 돈을 받고 엄격한 사후 감독을 받는다는 점에서 영화 ‘기생충’에 나온 피자곽 접는 업무와 비슷하다”며 “개인적으로는 돈을 벌 수 있어 만족하지만 커리어나 직무 능력 개발에 도움은 전혀 안 된다”고 평가했다.
"취지는 좋지만 정부 주도는 안돼"
정부는 이 같은 일자리를 앞으로 10만개 만들어 청년에게 공급할 계획이다. 이미 행정안전부와 과기부 등은 연내 1000억원 가량을 들여 데이터 라벨링 인턴 및 전문 일자리를 1만개 만들겠다고 밝혔다. 대부분은 4개월짜리 '단기 알바'다. 신종 코로나바이러스 감염증(코로나19)으로 인한 청년들의 어려움을 완충하려는 '공공 근로' 성격이 크다.문제는 이렇게 만들어진 데이터들이 쓸모 없을 가능성이 높다는 점이다. 먼저 데이터의 품질 문제가 지적된다. 기자가 체험한 업체 등 민간 플랫폼들은 건마다 까다로운 심사를 거쳐 작업료를 지불하고 있다. "심사가 너무 느리고 까다롭다"는 불만이 많을 정도다. 이는 자동학습 AI의 성능을 높이려면 데이터의 '질'이 그만큼 중요해서다. 질 낮은 데이터, 즉 배웠던 것과 전혀 다른 거짓말투성이 데이터를 자동학습 AI가 봤다가는 성능이 오히려 저하될 수 있다. 기존에 공부한 것도 모르게 된다는 얘기다.
하지만 정부의 데이터 라벨링 일자리는 공공근로 성격이 강해 건수가 아닌 시급으로 임금을 지급한다. 극단적으로 말해 한 시간 내내 틀린 데이터셋 한두 개만 만들어도 월 200만원 가량을 받을 수 있다는 얘기다. 일을 집중해서 해야 할 유인이 그만큼 떨어지고, 만든 데이터의 신뢰성도 의심받을 수 밖에 없다.
수요자가 원하는 정보가 아닌 '공급자 위주'의 데이터 공급이라는 점도 문제로 지적된다. 자율주행차나 스마트시티 등 일단 데이터를 이용할 목적과 사업 계획이 뚜렷해야 실제 산업에서 사용이 가능한 AI 학습용 데이터를 만들 수 있다는 게 전문가들의 지적이다. 국책연구기관의 한 관계자는 “일단 데이터부터 만든 다음에 사용처를 고민해보자는 것은 '벽돌을 들판에 던져놓으면 빌딩이 된다'는 것과 다름이 없다”며 “집을 지을 때 설계를 한 뒤 맞는 재료를 만들어 공급하듯이 데이터도 맞춤형으로 만들지 않으면 '정크 데이터'가 될 것”이라고 지적했다.
이런 문제점들은 데이터를 '정부 주도'로 구축하려는 시도에서 비롯됐다는 분석이 나온다. 해외 IT 기업들은 개발도상국 근로자 등에 데이터 라벨링 작업을 맡기고 있다. 언어와 관련 없는 작업이라면 부담없이 맡길 수 있는 데다 임금도 시간당 2달러 정도에 불과하다. 자동학습 AI가 사용할 데이터조차도 또다른 자동학습 AI로 만들기 위한 시도도 계속 이뤄지고 있다. 데이터 라벨링 관련 민간 산업이 한국에서는 이제 기지개를 막 켜는 수준인데, 정부의 개입으로 발전이 저해될 것이라는 우려도 있다.
정부 관계자는 "디지털 뉴딜은 아직 큰 윤곽이 제시된 것이고, 단기 일자리를 만드는 것은 코로나19 극복을 위한 경기 대응 성격도 크다"며 "업계에서 제기되는 문제점을 주의깊게 듣고 있으며 향후 발표할 추가 계획 등에 이를 반영해 보완해 나가겠다"고 말했다.
성수영 기자 syoung@hankyung.com